Pandas Text Read Add New Row Every Nth Element

Programming Tips
12 Means to Apply a Part to Each Row in Pandas DataFrame
How to profile performance and balance it with ease of use
![]()
Applying a function to all rows in a Pandas DataFrame is ane of the most common operations during data wrangling. Pandas DataFrame use office is the near obvious choice for doing information technology. It takes a function equally an argument and applies information technology forth an centrality of the DataFrame. However, it is not e'er the best choice.
In this commodity, you will measure the performance of 12 alternatives. With a companion Code Lab, you lot can attempt information technology all in your browser. No demand to install anything on your automobile.
Trouble
Recently, I w as analyzing user behavior data for an e-commerce app. Depending on the number of times a user did text and voice searches, I assigned each user to one of four cohorts:
- No Search: Users who did no search at all
- Text Just: Users who did text searches only
- Vocalization Only: Users who did voice searches only
- Both: Users who did both text and vocalisation search
It was a huge data set with 100k to a one thousand thousand users depending upon the called fourth dimension piece. Computing information technology with Pandas apply part was excruciatingly slow, and then I evaluated alternatives. This commodity is the distilled lessons from that.
I can't share that dataset. Then I am picking another similar problem to show the solutions: the Eisenhower method.
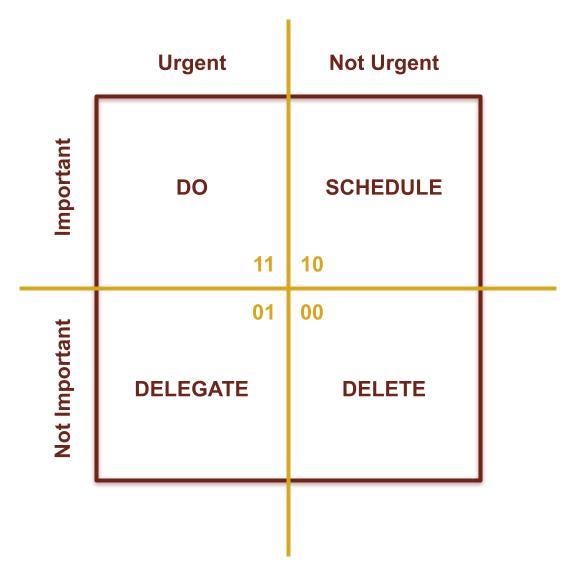
Based on a chore's importance and urgency, the Eisenhower Method assigns it into ane of four bins. Each bin has an associated action:
- Of import and Urgent: Practice correct away
- Important simply non Urgent: Schedule for subsequently
- Non Important but Urgent: Delegate to someone else
- Neither Of import nor Urgent: Delete time wasters.
Nosotros volition use the boolean matrix shown in the adjacent figure. Importance and urgency booleans make the binary integer value for each action: Exercise(three), SCHEDULE(2), Consul(1), DELETE(0).
We will profile the performance of mapping tasks to one of the deportment. Nosotros will measure which of the 12 alternatives take the least corporeality of fourth dimension. And we will plot the operation for upward to a 1000000 tasks.
It is a expert time to open the companion notebook at Google Colab or Kaggle. If you want to see the code in action, you tin execute the cells in the Code Lab as you read along. Go ahead, execute all the cells in the Setup section.
Test Information
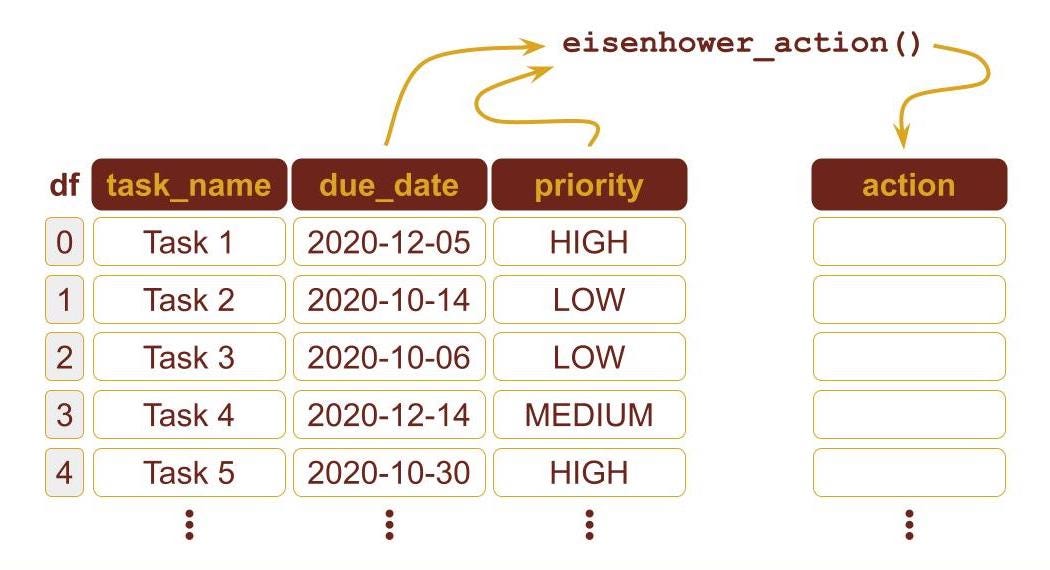
Faker is a handy library to generate data. In the Code Lab, it is used for generating a DataFrame with a 1000000 tasks. Each task is a row in the DataFrame. It consists of task_name (str), due_date (datetime.date), and priority (str). Priority tin be 1 of the three values: LOW, MEDIUM, HIGH.

Optimize DataFrame Storage
We will minimize the storage size to eliminate its effect on any of the alternatives. The DataFrame with ~two one thousand thousand rows is taking 48MB:
>>> test_data_set.info() <class 'pandas.core.frame.DataFrame'>
RangeIndex: 2097153 entries, 0 to 2097152
Information columns (full 3 columns):
# Cavalcade Dtype
--- ------ -----
0 task_name object
i due_date object
2 priority object
dtypes: object(iii)
memory usage: 48.0+ MB
Instead of str, priority can be stored equally Pandas chiselled blazon:
priority_dtype = pd.api.types.CategoricalDtype(
categories=['LOW', 'MEDIUM', 'Loftier'],
ordered=True
) test_data_set['priority'] = test_data_set['priority'].astype(priority_dtype)
Let'southward check out the DataFrame size at present:
>>> test_data_set.info() <class 'pandas.cadre.frame.DataFrame'>
RangeIndex: 2097153 entries, 0 to 2097152
Data columns (total 3 columns):
# Column Dtype
--- ------ -----
0 task_name object
1 due_date object
2 priority category
dtypes: category(1), object(two)
memory usage: 34.0+MB
Size is reduced to 34MB.
Eisenhower Activity Function
Given importance and urgency, eisenhower_action computes an integer value between 0 and 3.
def eisenhower_action(is_important: bool, is_urgent: bool) -> int:
render 2 * is_important + is_urgent For this practice, we will assume that a task with HIGH priority is of import. If the due date is in the next two days, so the task is urgent.
The Eisenhower Action for a job (i.e. a row in the DataFrame) is computed by using the due_date and priority columns:
>>> cutoff_date = datetime.date.today() + datetime.timedelta(days=ii) >>> eisenhower_action(
test_data_set.loc[0].priority == 'HIGH',
test_data_set.loc[0].due_date <= cutoff_date
) 2
The integer 2 means that the needed action is to SCHEDULE.
In the rest of the article, we will evaluate 12 alternatives for applying eisenhower_action function to DataFrame rows. First, nosotros will mensurate the time for a sample of 100k rows. Then, we will mensurate and plot the fourth dimension for upwards to a million rows.
Method 1. Loop Over All Rows of a DataFrame
The simplest method to procedure each row in the good old Python loop. This is plain the worst way, and nobody in the right listen will always do it.
def loop_impl(df):
cutoff_date = datetime.engagement.today() + datetime.timedelta(days=2) issue = []
for i in range(len(df)):
row = df.iloc[i]
result.suspend(
eisenhower_action(
row.priority == 'HIGH', row.due_date <= cutoff_date)
) return pd.Serial(effect)
As expected, information technology takes a horrendous corporeality of time: 56.6 seconds.
%timeit data_sample['action_loop'] = loop_impl(data_sample) one loop, best of 5: 56.6 s per loop
Information technology establishes the worst-case functioning upper bound. Since its price is linear, i.e. O(n), information technology provides a practiced baseline to compare other alternatives.
Line Level Profiling
Let's find out what is taking so long using the line_profiler, only for a smaller sample of 100 rows:
%lprun -f loop_impl loop_impl(test_data_sample(100)) Its output is shown in the post-obit figure:

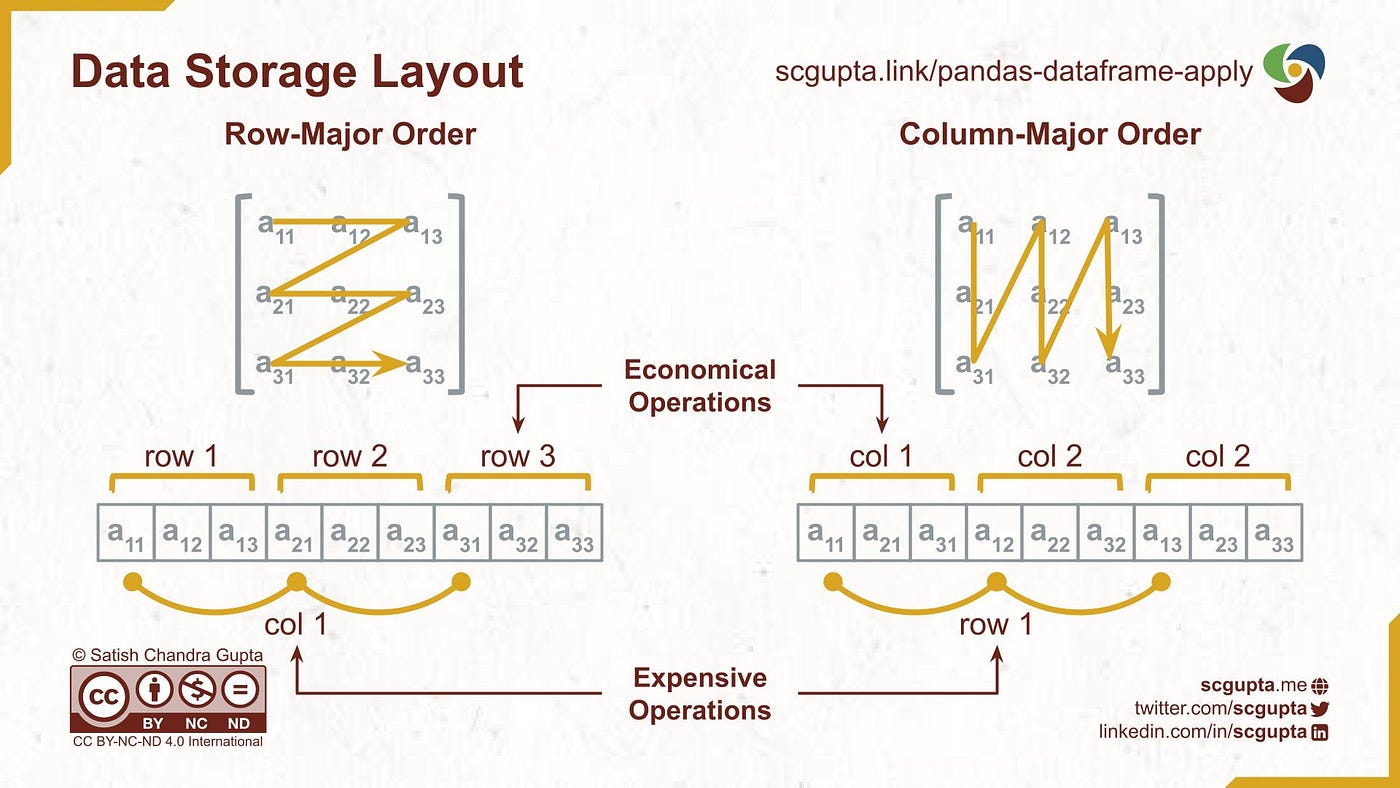
Extracting a row from DataFrame (line #six) takes ninety% of the time. That is understandable because Pandas DataFrame storage is column-major: consecutive elements in a column are stored sequentially in memory. So pulling together elements of a row is expensive.
Fifty-fifty if nosotros have out that 90% toll from 56.6s for 100k rows, it would have five.66s. That is still a lot.
Method 2. Iterate over rows with iterrows Part
Instead of processing each row in a Python loop, let's attempt Pandas iterrows function.
def iterrows_impl(df):
cutoff_date = datetime.date.today() + datetime.timedelta(days=two) return pd.Series(
eisenhower_action(
row.priority == 'HIGH', row.due_date <= cutoff_date)
for index, row in df.iterrows()
)
It takes 9.04 seconds, approx. one-fourth of the fourth dimension taken by the loop:
%timeit data_sample['action_iterrow'] = iterrows_impl(data_sample) one loop, best of 5: nine.04 southward per loop
Method 3. Iterate over rows with itertuples Role
Pandas has another method, itertuples, that processes rows as tuples.
def itertuples_impl(df):
cutoff_date = datetime.engagement.today() + datetime.timedelta(days=2) render pd.Series(
eisenhower_action(
row.priority == 'HIGH', row.due_date <= cutoff_date)
for row in df.itertuples()
)
Its functioning threw a surprise, it took only 211 milliseconds.
%timeit data_sample['action_itertuples'] = itertuples_impl(data_sample) 1 loops, best of v: 211 ms per loop
Method 4. Pandas utilize Function to every row
Pandas DataFrame use function is quite versatile and is a popular choice. To make it process the rows, you take to pass axis=1 argument.
def apply_impl(df):
cutoff_date = datetime.date.today() + datetime.timedelta(days=2)
return df.apply(
lambda row:
eisenhower_action(
row.priority == 'HIGH', row.due_date <= cutoff_date),
centrality=ane
) This too threw a surprise for me. It took i.85 seconds. 10x worse than itertuples!
%timeit data_sample['action_impl'] = apply_impl(data_sample) 1 loop, best of 5: ane.85 s per loop
Method v. Python Listing Comprehension
A column in DataFrame is a Series that can be used as a list in a list comprehension expression:
[ foo(x) for x in df['x'] ] If multiple columns are needed, then zip can be used to make a list of tuples.
def list_impl(df):
cutoff_date = datetime.appointment.today() + datetime.timedelta(days=two)
return pd.Series([
eisenhower_action(priority == 'Loftier', due_date <= cutoff_date)
for (priority, due_date) in naught(df['priority'], df['due_date'])
]) This also threw a surprise. It took but 78.4 milliseconds, even better than itertuples!
%timeit data_sample['action_list'] = list_impl(data_sample) 10 loops, all-time of 5: 78.4 ms per loop
Method 6. Python map Function
Python's map function that takes in function and iterables of parameters, and yields results.
def map_impl(df):
cutoff_date = datetime.date.today() + datetime.timedelta(days=2)
render pd.Series(
map(eisenhower_action,
df['priority'] == 'HIGH',
df['due_date'] <= cutoff_date)
) This performed slightly amend than listing comprehension.
%timeit data_sample['action_map'] = map_impl(data_sample) 10 loops, best of 5: 71.5 ms per loop
Method 7. Vectorization
The real ability of Pandas shows upwardly in vectorization. Only it requires unpacking the office as a vector expression.
def vec_impl(df):
cutoff_date = datetime.date.today() + datetime.timedelta(days=2)
return (
two*(df['priority'] == 'Loftier') + (df['due_date'] <= cutoff_date)) Information technology gives the best performance: only xx milliseconds.
%timeit data_sample['action_vec'] = vec_impl(data_sample) 10 loops, all-time of 5: 20 ms per loop
Vectorizing, depending upon the complication of the function, tin can take pregnant endeavour. Sometimes, it may non even exist feasible.
Method 8. NumPy vectorize Function
NumPy offers alternatives for migrating from Python to Numpy through vectorization. For example, it has a vectorize() role that vectorzie any scalar function to accept and render NumPy arrays.
def np_vec_impl(df):
cutoff_date = datetime.engagement.today() + datetime.timedelta(days=2)
render np.vectorize(eisenhower_action)(
df['priority'] == 'Loftier',
df['due_date'] <= cutoff_date
) Non surprisingly, its performance is second to merely Pandas vectorization: 35.7 milliseconds.
%timeit data_sample['action_np_vec'] = np_vec_impl(data_sample) 10 loops, all-time of 5: 35.seven ms per loop
Method 9. Numba Decorators
So far, simply Pandas and NumPy packages were used. Just in that location are more alternatives if you are open to having boosted bundle dependencies.
Numba is commonly used to speed up applying mathematical functions. It has various decorators for JIT compilation and vectorization.
import numba @numba.vectorize
def eisenhower_action(is_important: bool, is_urgent: bool) -> int:
return ii * is_important + is_urgent def numba_impl(df):
cutoff_date = datetime.engagement.today() + datetime.timedelta(days=2)
return eisenhower_action(
(df['priority'] == 'HIGH').to_numpy(),
(df['due_date'] <= cutoff_date).to_numpy()
)
Its vectorize decorator is similar to NumPy vectorize part but offers better performance: 18.nine milliseconds (similar to Pandas vectorization). Merely it also gives cache alarm.
%timeit data_sample['action_numba'] = numba_impl(data_sample) The slowest run took xi.66 times longer than the fastest. This could mean that an intermediate result is being cached.
1 loop, best of v: eighteen.9 ms per loop
Method 10. Multiprocessing with pandarallel
The pandarallel package utilizes multiple CPUs and split the work into multiple threads.
from pandarallel import pandarallel pandarallel.initialize() def pandarallel_impl(df):
cutoff_date = datetime.engagement.today() + datetime.timedelta(days=2)
return df.parallel_apply(
lambda row: eisenhower_action(
row.priority == 'HIGH', row.due_date <= cutoff_date),
axis=ane
)
In ii-CPU machine, information technology took 2.27 seconds. The splitting and bookkeeping overheads don't seem to pay off for 100k records and 2-CPU.
%timeit data_sample['action_pandarallel'] = pandarallel_impl(data_sample) 1 loop, best of v: 2.27 due south per loop
Method 11. Parallelize with Dask
Dask is a parallel computing library that supports scaling up NumPy, Pandas, Scikit-acquire, and many other Python libraries. It offers efficient infra for processing a massive amount of data on multi-node clusters.
import dask.dataframe as dd def dask_impl(df):
cutoff_date = datetime.engagement.today() + datetime.timedelta(days=2)
return dd.from_pandas(df, npartitions=CPU_COUNT).employ(
lambda row: eisenhower_action(
row.priority == 'HIGH', row.due_date <= cutoff_date),
axis=1,
meta=(int)
).compute()
In 2-CPU car, information technology took ii.13 seconds. Like pandarallel, payoffs are meaningful merely when processing a big amount of information on many machines.
%timeit data_sample['action_dask'] = dask_impl(data_sample) i loop, best of five: 2.thirteen s per loop
Method 12. Opportunistic Parallelization with Swifter
Swifter automatically decides which is faster: to use Dask parallel processing or a elementary Pandas utilise. Information technology is very simple to utilise: only all one word to how one uses Pandas apply function: df.swifter.apply.
import swifter def swifter_impl(df):
cutoff_date = datetime.date.today() + datetime.timedelta(days=2)
return df.swifter.utilize(
lambda row: eisenhower_action(
row.priority == 'High', row.due_date <= cutoff_date),
axis=1
)
Its operation for this employ instance is expectedly quite shut to Pandas vectorization.
%timeit data_sample['action_swifter'] = swifter_impl(data_sample) 10 loops, best of 5: 22.ix ms per loop+
Plot Functioning Over DataFrame Size
Plotting is helpful in understanding the relative performance of alternatives over input size. Perfplot is a handy tool for that. It requires a setup to generate input of a given size and a list of implementations to compare.
kernels = [
loop_impl,
iterrows_impl,
itertuples_impl,
apply_impl,
list_impl,
vec_impl,
np_vec_impl,
numba_impl,
pandarallel_impl,
dask_impl,
swifter_impl
] labels = [str(grand.__name__)[:-five] for 1000 in kernels] perfplot.prove(
setup=lambda n: test_data_sample(northward),
kernels=kernels,
labels=labels,
n_range=[two**thousand for k in range(K_MAX)],
xlabel='North',
logx=Truthful,
logy=True,
#equality_check=None
)
It generates a plot like the ane shown below.
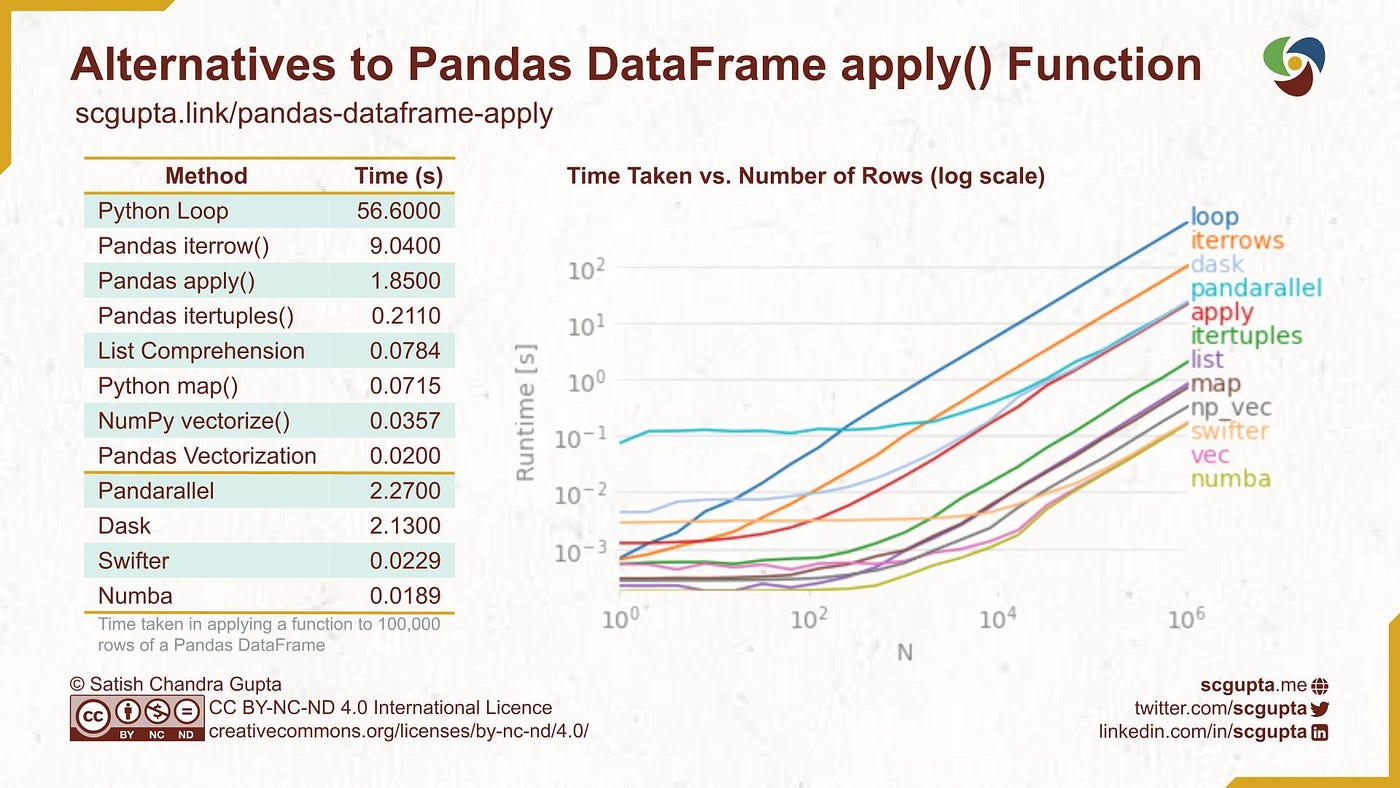
Here are some observations from the plot:
- For this apply case, the asymptotic operation club stabilizes at near 10k rows in the DataFrame.
- Since all lines in the plot go parallel, the perf departure might not exist credible in the log-log scale plot.
- The
itertuplesis equally simple to use asapplybut with 10x ameliorate performance. - List Comprehension is ~2.5x better than
itertuples, though it tin can be verbose to write for a complex function. - NumPy
vectorizeis 2x better than the Listing comprehension, and is as simple to use equallyitertuplesandapplyfunctions. - Pandas vectorization is ~2x better than NumPy
vectorize. - Overheads of parallel processing pay off merely when a huge amount of information is processed on many machines.
Recommendations
Performing an operation independently to all Pandas rows is a common demand. Here are my recommendations:
- Vectorize DataFrame expression: Go for this whenever possible.
- NumPy
vectorize: Its API is not very complicated. It does not require additional packages. It offers almost the best performance. Choose this if vectorizing DataFrame isn't infeasible. - List Comprehension: Opt for this alternative when needing only 2–3 DataFrame columns, and DataFrame vectorization and NumPy vectorize not infeasible for some reason.
- Pandas
itertuplesfunction: Its API is likeusefunction, just offers 10x better performance thanemploy. Information technology is the easiest and most readable option. Information technology offers reasonable performance. Do this if the previous three do not work out. - Numba or Swift: Use this to exploit parallelization without code complexity.
Understanding the cost of various alternatives is disquisitional for making an informed choice. Use timeit, line_profiler, and perfplot to mensurate the performance of these alternatives. Balance performance with ease of use for deciding the best alternative for your utilise case.
If you enjoyed this, please:
Share it with this infographic:

Source: https://towardsdatascience.com/apply-function-to-pandas-dataframe-rows-76df74165ee4
{kind=link}
Posting Komentar untuk "Pandas Text Read Add New Row Every Nth Element"